
心理学家的研表究明: 人在三岁左右的时候如果接受了"正确"的教育, 就可以掌握"正确"的初步行为规范, 对自己一段时间的行为进行约束.
A Method to Discover Digital Collaborative Conversations in Business Collaborations
| 许多数字工具都旨在促进办公人员之间的协作,如消息服务和会议工具.在协作期间或结束时通常会生成文档,而没有在最初就参与协作的人员往往难以理解该文档的部分内容,其由于缺乏整体的背景知识.此文考虑到数字工具所包含的宝贵的上下文中的协作知识可用于理解文档.此文的研究目标是在文档生成期间,重建通过消息服务进行的会话和它们转到会议工具的链接.此文的方法的贡献之处在于结合了几种会话流方法来识别不同会话之间关注的链接,特别地将标头信息通过社会、时间和语义上的近似性予以结合.研究结果表明消息服务和会议工具是以互补的方式使用的.主要结果证实结合不同的会话流方法可以有效地检测和构造来自同一文档的不同数字协作会话的会话流. |
| 会话流; 显性知识; 隐性知识; 数字通信与协作工具; 文档制作的协作对话 |
Problem
随着互联网行业的发展,促进通信和协作的数字应用程序数量大幅增加,这里将其称为数字通协工具 (Digital Communication and Collaboration Tools, DCCT).协作活动的主要媒介是文档. 生成文档最终版本之前的协作过程中可能需要利用协作者其深度且默契的知识进行深入讨论. 但文档的最终版本很少包含如何产生该文档的基本理论依据,而且过程中所做决定的丰富背景可能隐藏在协作者之间的数字交换物中,这里将其称为文档生成的协作会话(Collaborative Conversation of Document Production, CCDP).
对于一个新的协作者,CCDP中隐藏的元素可能是快速理解文档生成过程中所做决定的关键,而可免去联系原始协作者.如何将DCCT中的宝贵知识用来促进未来协作是此文面临的问题.
此文回顾了DCCT的内容和使用方法,研究目的是提取和重建CCDP, 即在文档生成期间重建通过消息服务进行的会话和它们转到会议工具的链接.文章讨论了对协作知识的相关工作,在这种设定下数字工具的使用,以及关于会话流的最近工作--互联网消息的树分类.研究的更大目标是创建一个知识库, 用于存储关于协作的宝贵的可重用知识: 这将使未来的协作更加高效和有效.此文所描述的工作还通过分析协作过程中的电子邮件交换来丰富数据库中的元数据,更好地理解将电子邮件与会议工具结合使用的互补性.
Related Works
协作中的知识 (Knowledge in Collaborations)
we can know more than we can tell -- Polanyi
目前知识是一个动态的概念, 从明晰的内容到默契所依赖的内容
对于协作生成的文档,其内容被视为显性知识,而理解其生成的过程被视为揭示隐性知识.
数字通协工具 (Digital Communication and Collaboration Tools, DCCT)
研究发现新的DCCT并没有取代老的DCCT, 而是以一种互补的方式在使用, 呈现了一种被称作” Napoleon effect”的堆叠效果, 如办公时并用腾讯微信, 网易邮箱以及百度云盘. 新出品的阿里钉钉由于其同时具有社交和办公功能而逐渐占据市场, 这也从侧面证明了不同DCCT的互补性. 研究表明协作的方式可取决于协作的类型, 涉及的协作者以及使用的媒介. 此文认为每个服务不应在CCDP中单独考虑, 而是作为知识工作者可用的一套DCCT中的一个. 为了提取CCDP的知识, 此文将研究重点放在电子邮件及其与CoopNet的链接上.
会话线 (Conversation Threading)
会话线是DCCT提供的一项功能,其方便地对互联网消息及其答复进行分组.RFC5322指定了通过电子邮件发送的文本消息的语法,电子邮件中的标题文本为会话线提供一种实现模式:字段”references”和“in reply to”可用于标识会话线,即存储ID以检索电子邮件会话的来源,答复,转发或CCS.但由于这类属性仅适用于电子邮件客户端而非服务器,为了从DCCT进行对话,经典方法是采用电子邮件中的其他三个属性:文本内容,合作者和发送时间进行相似度匹配.而后有人用自然语言处理(Natural Language Processing, NLP)工具对相似度匹配的对象进行了扩展.最新研究提出:会话树的重建,在于识别会话线内的回复结构, 即会话之间的逻辑联系.
文档制作的合作对话 (Collaborative Conversation of Document Production, CCDP)
我们根据两个标准定义 CCDP : 关于文件的编制和共享的信息交流, 以及 DCCT之间的互补性。
- 对于前者, 我们保留三个属性来标识会话线程: 一组协作者, 在有限的时间内处理同一主题。
- 对于后者, 我们关注的是橙色两个最常用的 Dcct 之间的互补性: 消息传递服务及其与会议工具的链接.
已有会话线 (Existing Conversation Thread, ECT)
消息服务和会议工具的会话线往往是独立的(没有共同的索引).但在实践中,协作人员通常会使用其消息服务向电话会议发送邀请或报告电话会议.为确定消息服务和会议工具的互补性, 应区分消息服务的三种类型的消息: 邮件,会议(如邮件日历中显示)和会议通知(如邀请、接受).研究目标是重建这三种类型的消息的ECT,并在它们之间找到新的相关链接.
协作会话线 (Collaborative Conversation Thread, CCT)
协作会话线是由来自不同ECT的两个消息之间的近似性组成的加权链接。协作会话线在逻辑上将不同的ECT连接在一起,以构成CCDP.
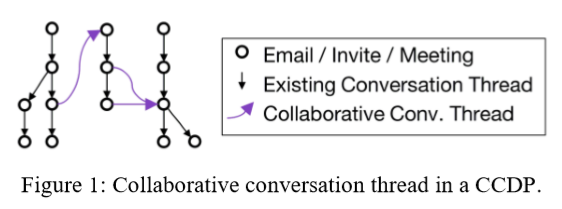
Modus
此文回顾了DCCT的内容和使用方法,研究目的是提取和重建CCDP的会话线, 即在文档生成期间重建通过消息服务进行的会话和它们转到会议工具的链接.文章讨论了对协作知识的相关工作,在这种设定下数字工具的使用,以及关于会话线的最近工作--互联网消息的树分类.研究的更大目标是创建一个知识库, 用于存储关于协作的宝贵的可重用知识:这将使未来的协作更加高效和有效.此文所描述的工作还通过分析协作过程中的电子邮件交换来丰富数据库中的元数据,更好地理解将电子邮件与会议工具结合使用的互补性.
首先, 定义式(1)来确定连接不同的ECT; 然后, 人为应用式(1)及其衍生定义进行先行定性评估.
全局接近度 (Global Proximity, GP)
考虑两条信息(来自电子邮件,会议邀请或会议)的全局近似度![]() . 如果ECT高于某个阈值,且两个消息属于不同的ECT,则方法认为检测到了一组CCT,并将这些ECT分配给相同的CCDP.
. 如果ECT高于某个阈值,且两个消息属于不同的ECT,则方法认为检测到了一组CCT,并将这些ECT分配给相同的CCDP.
形式化地定义![]() 为三个近似度(会话者近似度
为三个近似度(会话者近似度![]() ,时间近似度
,时间近似度![]() ,语义近似度
,语义近似度![]() )的加权平均值:,
)的加权平均值:,
|
|
| (1) |
式(1)中所有的近似度的值均在[0,1]范围内.系数![]() 、
、![]() 和
和![]() 用于调整子近似度因素对全局近似度带来的影响.
用于调整子近似度因素对全局近似度带来的影响.
会话者近似度 (Interlocutors Proximity, IP)
会话者近似度PI![]() 旨在确定会话者通过协作之间的联系.消息服务可以识别互联网信息中会话者的三种不同角色:”From”, ”To”, ”CC” (RFC 5322).这里新定义“Absent”, 在不属于前三者时使用.
旨在确定会话者通过协作之间的联系.消息服务可以识别互联网信息中会话者的三种不同角色:”From”, ”To”, ”CC” (RFC 5322).这里新定义“Absent”, 在不属于前三者时使用.
形式化地定义PI![]() 为会话中涉及的每个角色关于PI的系数的组合:
为会话中涉及的每个角色关于PI的系数的组合:
|
|
| (2) |
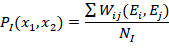
其中![]() 为会话者的总数,每一个消息的会话者
为会话者的总数,每一个消息的会话者![]() 之间有一个[0,1]的系数
之间有一个[0,1]的系数![]() ,其反映了协作者的角色的变化,如表(Table 1)所示
,其反映了协作者的角色的变化,如表(Table 1)所示
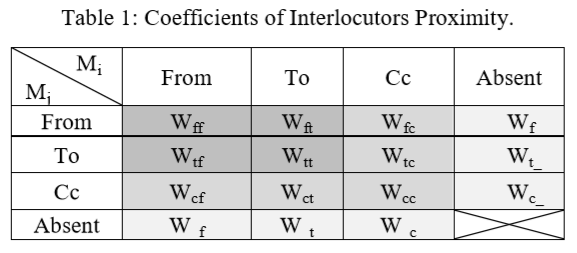
Table 1中, 涉及”From”, ”To”的系数被设计成具有更高的值,而涉及“Absent”的系数值较低.
时间近似度 (Time Proximity, TP)
考虑两条信息其发送时间的差异 形式化地定义![]() 为发送时间差
为发送时间差![]() 的指数逆函数:
的指数逆函数:
|
|
| (3) |
这里![]() 可能会被修改为具有不同的时间粒度(
可能会被修改为具有不同的时间粒度(![]() 须在同一粒度下)
须在同一粒度下)
语义近似度 (Semantic Proximity, SP)
考虑用电子邮件的正文内容或附件内容来计算语义上的近似度![]() ,形式化地定义
,形式化地定义![]() 为三个语义的子近似度(主题语义近似度
为三个语义的子近似度(主题语义近似度![]() ,附件语义近似度
,附件语义近似度![]() ,跨语义近似度
,跨语义近似度![]() )的最高的值:
)的最高的值:
|
|
| (4) |
为了计算这些语义的子近似度, 使用了称为SimBow的语义度计算工具[2]: :如果两个文本是语义上的接近的, 则计算出的近似度倾向于1;反之,近似度倾向于0.
学科语义接近度 (SSP)
为了计算 SSP, 我们删除了主题文本的可能前缀 "re" 或 "FWD", 并使用Simow为我们提供了两个文本之间的语义接近度。如果比较的两条消息中至少有一条具有空主题文本字段,则不需要使用simbo和 ssp = 0.
附件语义接近度 (ASP)
ASP 的计算方式与 SSP 类似。当邮件有多个附件时, 我们当前将它们的名称连接到一个字符
串中。之所以选择这种简单的方法, 是因为它为我们提供了在语义上比较附件的第一步。如果要比较的两个互联网消息中至少有一个没有任何附件, 则不需要使用 simbow 和 asp = 0.
横交式接近度 (CSP)
CSP 可用于标识邮件的主题文本 (子 j) 与另一邮件的附件 (att)的名称之间的语义接近度。对于两个互联网消息mi 和mj,我们将 csp 定义为:
|
|
| (5) |
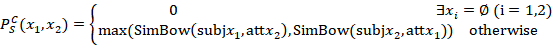
与 SSP 和 ASP 一样, 如果两个文本字段中至少有一个为空, 则 CSP = 0。
接近度的计算
这些方程首先是在一个小数据集的消息交换上尝试的, 这些数据集是由一位知识工作者选择的, 他在自己的工作中认为它们是 CCDP。
此 CCDP 由3个对话组成。7次交流的第一次对话从一个行政人员要求研究项目负责人结束一个项目开始。然后, 后者将信息传递给相关人员, 要求他们准备 powerpoint 文档。第二次对话由两个交易所组成,要求召开电话会议, "正式" 结束该项目。第三次谈话涉及邀请参加所要求的电话会议和分发会议报告.
尽管这三个对话是不同的, 并且具有不同的主题, 但它们在逻辑上是相互关联的, 因为它们与相同的目标 ("项目关闭") 和随着时间的推移而演变的powerpoint文档的共享版本相关。数据集构建后, 四个协作者各自主观地将全局接近度测量归因于每一对消息。请注意, 合作者知道消息的正文内容, 而我们的公式尚未考虑到这一点。 我们将这个主观全球近似点的小样本称为黄金标准。这是通过平均四个主观全局接近度计算的。
为了评估和验证我们的方程, 我们将黄金标准与计算的近似度进行比较。
实验结果
实验结果比较了经典标准和文章给出的方法计算的近似度之间的差异,得到了比较好的结果并给出了对应的参数值.由于参数值很多很杂,这里不一一列举.文章还单独分析了各个子近似度.将阈值应用于"黄金标准"值可识别主观近似度最高的对消息.且采用补偿系数于计算近似度.并对个近似度进行了定量的分析.
数据分散分析
虽然数据集很小,但我们分析数据色散, 以便比较黄金标准和计算的接近度之间的差异。我们查看全局任意两条消息之间的近似值, 以及属于同一会话线程的消息之间的近似值, 或指向不同会话线程的消息之间的近似值。表3显示了全局级别的结果, 而不管两条消息是否属于同一 ECT。
平均绝对偏差可能在0和1之间变化。因此,任何值都表示 "黄金标准" 和 "计算的接近度" 之间的错误率, 该错误率可以按百分比进行转换。因此, 通过全局水平分析, 我们得到的平均绝对偏差为 0.186, 即18.6% 的错误率。因此, 跟不能不的接近度与黄金标准有很大的不同, 因此它们不是很令人满意。
表3中0.186 的平均绝对偏差主要是由于不同 Ect 的消息之间的平均绝对偏差, 该偏差值为 0.186 (表 5), 错误率为24.1%。表3中的平均绝对偏差相对较低 (11%)表示在同一 ECT 中的两条消息之间进行了近似值计算。然而, 表5中的平均绝对偏差为 0.241, 这意味着我们应该改进近似值的计算, 当应用方程对来自不同 ect的消息.
接近平衡
我们还分析了亚近度.将阈值应用于 "黄金标准" 值可识别主观接近度最高的对消息.然而,中的数据色散分析.工作台3 个表示我们不能直接将黄金标准与计算出的 prox 进行比较由于两组数据之间的差异, 特别是在平均值方面的差异, 实在是太大了.因此,我们对黄金标准应用一个补偿系数, 使其平均值等于计算的接近度 (表 6).
我们将补偿系数应用于计算的近处, 而不是黄金标准 (这是参考)。但是, 某些 Cp 的值大于 1, 这是毫无意义的。
应用此补偿系数后, 黄金之间的平均绝对偏差
标准和计算的近似值从0.186 到0.186 不等, 在数据集分散之间差异较小的情况下进行了更合理的比较。
接近度分析
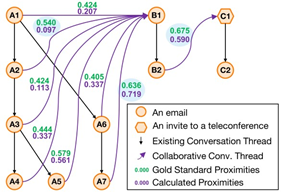 、
、
图2显示了协作会话线程的计算接近度。我们关注的是三个会话线程 (a、b 和 c) 之间值最高的黄金标准近似值。一个有趣的计算接近度是消息 A7 和 B1 之间的距离, 这属于不同的 Ect, 并共享与对话 a 的主题相同的附件名称。计算的接近度为0.719, 黄金标准值为 0.719, 接近 (小于 0.1)。从表7的次近似值中看, 语义和时间近似值分别为1和 0.9 77, 而对话者的接近度仅为0.179。这意味着通过计算近似值, 已经确定了一个协作线程
(并通过黄金标准验证), 这种合作是由于信息在语义上和时间上是接近的, 而不是由于对话者的亲密。
此外, 这种计算的接近度对应于一对消息, 这对消息在黄金标准中具有第二高的接近值, 这表明近似值的计算与人的关系是相关的。更确切地说, 我们可以看到, A7 和 B1 之间的计算接近度大于 B1和对话 a 的其他消息之间的计算接近度 (图 2), 正如知识工作者在黄金标准中所做的那样。
第二个计算出的兴趣接近度是黄金标准中 B2 和 C1 之间的最高接近值。此计算的接近度接近黄金标准值 (分别为0.590 和 0.590)。这是令人鼓舞的, 因为它表明我们的方法是有效的, 显著地链接不同的对话, 涉及文档生产中的协作。
一些计算出的接近度与黄金标准有很大不同, 例如消息 A2 和 B1
计算出的接近度与黄金标准有很大不同, 因为该公式没有考虑到身体内容。因此,它无法在 a2 和 B1 之间进行任何语义上的接近
此文介绍了一种将主场方法和近似方法相结合的会话线处理方法。由于头场方法不足以在客户端消息服务上进行会话线处理, 因此它是通过在消息之间计算社交、时间和语义近似度的近似方法完成的。研究结果表明了设计的近似度表达式可以检测到消息服务和会议工具在文档生成过程中的互补使用。此外,还表明不同的会话线处理方法的结合对于在不同的数字会话涉及同一文档时将其链接起来是很有用的。文章的方法对于构建一个知识库是有用的,该知识库将有助于在有效的情况下编写文档.同时由于方法可以识别同一会话中两条消息之间不太相关的近似值,可据其删除那些可能与协作无关的消息:这有助于更清楚地强调未来知识库中的要素以帮助协作.文章的方法可以使用在类似于腾讯TIM,阿里钉钉,网易邮箱大师这类App设计上.
Fonus
- Alimam, M., Bertin, E., & Crespi, N., 2016. Enterprise 2.0–Literature Taxonomy and Usage Evaluation. IFIP Working Conference on The Practice of Enterprise Modeling. Springer, Cham, pp. 26-40.
- Charlet, D., Damnati, G., 2017. Simbow at semeval-2017 task 3: Soft-cosine semantic similarity between questions for community question answering. In: Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), pp. 315-319.
- Domeniconi, G., Semertzidis, K. Moro, G., Lopez, V., Kotoulos, S., M. Daly, E., 2016 Identifying Conversational Message Threads by Integrating Classification and Data Clustering. In: International Conference on Data Management Technologies and Applications. Springer, Cham, pp. 25-46.
- Drucker, P. F., 1959. The Landmarks of Tomorrow. New York: Harper and Row.
- Flepp, A., Bourge, F., Dugdale, J., Marie-Cardot, T., 2017. Extraction de connaissances à partir de l’usage des outils professionnels de communication et de collaboration. In: Conférence Nationale d’Intelligence Artificielle, pp. 55-60. Éditors:Berger Levrault.
- Isaac, H., Kalika, M., Charki, N.B., 2008. An empirical investigation of e-mail use versus face-to-face meetings: Integrating the Napoleon effect perspective. Communications of the Association for Information Systems, vol. 22(1), article 27.
- Klimt, B., & Yang, Y., 2004. Introducing the Enron Corpus. Conference on Email and Anti-Spam (CEAS).
- Lecko, 2018. État de l’art de la transformation interne des organisations. [online] Available at: http://referentiel.lecko.fr/etatdelart_tome10/ [Accessed April 2018].
- Leclercq-Vandelannoitte, A., Bertin, E., Colléaux, A., 2017. EMAIL: SURIVOR OR WALKING DEAD? An exploratory study of the potential replacement of email by enterprise social networks. Association Information et Management, AIM2017.
- Microsoft.com, 2013. Finding related messages in a mailbox by using EWS in exchange 2010. [online] Available at: https://msdn.microsoft.com/enus/library/office/ff406135(v=exchg.140).aspx [Accessed April 2018].
- Orange.com, 2015. Orange lance son réseau social interne de 2ème génération à l’échelle mondiale. [online] Available at : https://www.orange.com/fr/PressRoom/communiques/communiques-2015/Orangelance-son-reseau-social-interne-de-2eme-generation-al-echelle-mondiale [Accessed April 2018].
- Organisation for Economic Co-operation and Development (OECD), 1996. The Knowledge-based [online] Available at: http://www.oecd.org/sti/sci-tech/1913021.pdf [Accessed April 2018]
- Palus, S., Kazienko, P. (2010). Conversation Threads Hidden within Email Server Logs. World Summit on Knowledge Society. Springer, Berlin, Heidelberg , pp. 407-413.
- Pralong, J., 2017. Mode collaboratif ou collaboratif à la mode ? Pourquoi les réseaux sociaux d’entreprise peinent encore à développer des comportements collaboratifs. [online] Available at: http://www.igsecoles.com/wp-content/uploads/pdf/rh-presse.pdf [Accessed April 2018].
- Polanyi, M., 1966. The tacit dimension. 1st ed. New-York: Doubleday.
- Resnick, P., 2008. Internet Message Format, RFC 5322, DOI 10.17487/RFC5322. [online] Request for Comments. Available at: [Accessed April 2018].
- Yeh, J.-Y. and Harnly, A., 2006. Email Thread Reassembly Using Similarity Matching. In: Proceedings of Conference on E-mail and Anti-Spam (CEAS’06).